Entretien avec Marion Charreau par Sarah Sauquet
« Les espaces se sont multipliés, morcelés et diversifiés. Il y en a aujourd’hui de toutes tailles et de toutes sortes, pour tous les usages et pour toutes les fonctions. Vivre, c’est passer d’un espace à un autre, en essayant le plus possible de ne pas se cogner. » C’est dans son livre Espèces d’espaces que Georges Pérec, dont on connaît le goût pour la nomenclature et la classification, racontait comment l’histoire des sociétés était avant tout l’inscription dans un espace, à partir duquel et sur lequel on écrivait.
Marion Charreau, elle s’intéresse à l’histoire des langues, à leur transmission et à leur évolution, et a le talent de les mettre en images. Son ouvrage Le Français vu du ciel, paru en 2019 aux éditions Le Robert, est un incroyable voyage illustré au sein d’une contrée, la langue française, qu’elle nous présente comme des territoires à explorer. Riche et coloré, son livre permet une toute nouvelle approche du français, et séduira aussi bien spécialistes que néophytes. Nous avons souhaité en savoir plus sur la démarche de Marion, et l’intérêt pédagogique des « cartes mentales », ces cartes qui permettent de passer d’une notion linguistique à une autre sans jamais se cogner.
Sarah Sauquet : Pourrais-tu rapidement nous présenter Le Français vu du ciel, et nous raconter la genèse de ce projet ?
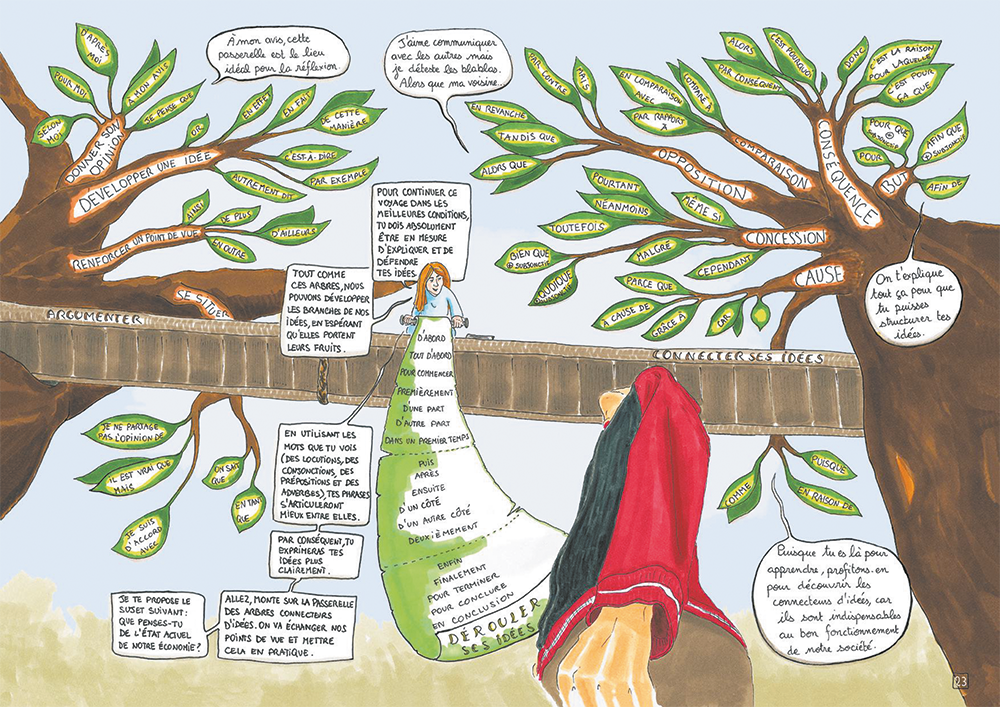
Marion Charreau : Le Français vu du ciel propose un voyage inédit dans la langue française. Il s’agit d’un beau livre au format BD qui présente la grammaire, la conjugaison et le lexique sous forme de cartes mentales illustrées, et reliées entre elles par les aventures d’un personnage. L’univers du livre est poétique, visuel et ludique.
Au début, un personnage observe un brouillard de mots (pronom, mode, complément, transitif, adjectif, etc.). Des mots que l’on utilise pour décrire la langue mais qui ne sont pas forcément clairs pour lui (ni pour nous). Curieux, il décide donc de partir en direction du brouillard et arrive dans les territoires des mots. Là, il va rencontrer les différents types de mots, comprendre leurs natures, leurs fonctions, et découvrir comment les utiliser pour exprimer sa pensée.
Avec Le Français vu du ciel, c’est un peu comme si on pouvait se déplacer dans les neurones d’une personne qui se pose des questions, comprend et apprend. En suivant le parcours et la progression du personnage, le lecteur décortique les mécanismes de la langue française, il clarifie et relie ses connaissances.
Ce livre est l’aboutissement de sept années d’enseignement du français à l’étranger à l’aide (notamment) des cartes mentales et d’une pratique de classe originale. À la demande d’enseignants souhaitant utiliser mes supports, l’idée de publier un livre a germé petit à petit. Rencontrer un éditeur qui ose parier sur ce projet a pris du temps. Mais voilà, c’est fait, Le Français vu du ciel est maintenant largement distribué.

Sarah Sauquet : Selon toi, à qui le livre s’adresse-t-il et quels usages peut-on faire des cartes mentales ?
Marion Charreau : Quand j’ai construit ce livre, j’ai toujours eu en tête une famille confortablement installée dans un canapé, discutant du français tout en naviguant dans les cartes. Le français vu du ciel est intergénérationnel, il s’adresse aux adolescents et aux adultes souhaitant rafraîchir leurs connaissances et se sentir à l’aise avec la langue. Mais il trouve d’autres publics : les enseignants qui s’en inspirent ou l’utilisent pour aborder certains points de grammaire en classe, les personnes qui apprennent le français langue étrangère, les personnes familiarisées avec les cartes mentales et la pensée visuelle, les professionnels de la pédagogie, les amateurs de beaux livres.
On peut utiliser les cartes mentales illustrées du livre pour avoir une vision d’ensemble des mécanismes de la langue française et se faire plaisir en apprenant. On peut consulter une carte en particulier pour revoir ou mémoriser un point de grammaire. On peut présenter un aspect de la langue sous un nouveau jour, s’inspirer des cartes pour parler de la langue autrement et associer des notions complexes à l’imaginaire des personnes qui nous écoutent. Ces cartes sont à la fois une proposition de voyage dans ses propres connaissances et un outil de discussion et de partage autour de la langue française.
Sarah Sauquet : L’ensemble, et c’est un tour de force, est à la fois extrêmement ordonné et construit tout en donnant une impression de profusion. Peux-tu nous en dire plus sur ton processus créatif, la façon dont tu as structuré et pensé l’ensemble ?
Marion Charreau : Pour créer, on part toujours de quelque chose d’existant. Dans le cas du livre, j’avais en stock et en mémoire des dizaines de cartes mentales sur la langue française réalisées pendant des années dans le cadre de cours de français.
J’ai tout de suite pensé le livre comme devant être un bel objet qui donne envie de se plonger dans les cartes. Puis j’ai dû trouver un fil conducteur (narratif et visuel) pour guider le lecteur et rendre le tout parfaitement cohérent.
Une fois les grandes lignes du livre définies, j’ai mis toutes ces informations dans une gigantesque carte mentale faite à l’aide d’un logiciel. Puis j’ai dessiné des cartes sur papier pour valider un prototype du livre auprès de l’éditeur et de l’équipe linguistique d’Orthodidacte.com qui a veillé sur ce projet. J’ai affiné le scénario, les cartes et l’univers visuel petit à petit, jusqu’à la réalisation des cartes originales. Pendant des mois, mon appartement a été envahi de cartes accrochées aux murs. J’ai littéralement vécu dans Le Français vu du ciel !
Sarah Sauquet : Dans ton livre, les notions grammaticales ou lexicales sont associées à des images (le tube des pronoms, les totems des modes, etc.). Comment ces choix se sont-ils faits ? Comment associes-tu une notion à une image ?
Marion Charreau : Certaines images viennent d’explications spontanées pendant les cours. J’aime beaucoup procéder par analogie pour aider quelqu’un à comprendre. J’ai aussi posé des questions du type « qu’est-ce qu’un verbe ? » à d’anciens élèves, des enseignants, des amis, des personnes d’âges et de nationalités différentes pour nourrir mon imaginaire et écouter ce qu’avait à dire mon futur public.
Au départ j’avais des images pour quelques notions seulement et puis petit à petit, l’univers des territoires des mots s’est construit et etoffé, imposant sa propre logique. C’était une sensation assez étrange, comme si ces lieux imaginaires devenaient autonomes.
Par exemple, si les noms sont des êtres sur une île et que les verbes se construisent dans la montagne, les pronoms sont logiquement reliés aux deux espaces en question car ils remplacent le nom mais sont aussi liés au verbe… C’est donc le tube des pronoms qui fait le lien entre l’île des noms et la montagne des verbes (par analogie avec le métro – tube en anglais qui est un moyen de déplacement relativement rapide comme chacun le sait). Dans une phrase, le pronom permet lui aussi d’aller plus vite, c’est une sorte de raccourci.

Sarah Sauquet : Le style graphique du livre est-il à l’image de ton style artistique habituel ? As-tu insisté sur certains aspects, travaillé certaines couleurs, ou souhaité avoir un rendu particulier ?
Marion Charreau : Comme je savais qu’il y aurait profusion d’informations, j’ai souhaité avoir un style graphique léger et organique pour mettre en avant les liens et donner une sensation de fluidité. Ce sont des éléments que l’on retrouve dans mon travail artistique mais il n’est pas visible sur Internet donc vous n’aurez pas d’élément de comparaison…
Je voulais aussi donner aux informations une texture, du relief. J’ai d’ailleurs observé beaucoup de lecteurs se déplacer dans le livre en caressant les pages.
Sarah Sauquet : Le livre est relativement exhaustif et aborde de nombreuses notions. Y a-t-il des notions ou thématiques que tu n’as pas voulu aborder, ou réussi à mettre en images ?
Marion Charreau : C’est vrai que ce livre donne une sensation réelle d’exhaustivité. Évidemment, il ne contient pas tous les aspects de la langue française, ce ne serait ni lisible ni utile, et aucun éditeur ne se risquerait à publier un livre aussi épais !
Le Français vu du ciel fait la synthèse de ce qui est vraiment nécessaire pour comprendre les mécanismes du français. Il contient les bases qui permettent de relier les notions essentielles aux plus complexes. Mon idée est que le lecteur puisse ensuite aller au-delà du livre avec l’assurance de l’expert et l’enthousiasme de l’explorateur. En naviguant dans les cartes et en suivant les aventures du personnage, on a l’agréable sensation que tout s’imbrique et se clarifie. On est donc prêt à poursuivre l’aventure.
Voici d’ailleurs un message pour les lecteurs : n’hésitez pas à prolonger les branches du Français vu du ciel par vous-même (dans votre tête ou avec un crayon) !
Sarah Sauquet : Pourrais-tu un jour concevoir un livre fondé sur le même principe et consacré au vocabulaire ? Peux-tu nous parler d’éventuels projets à venir ?
Marion Charreau : J’ai toute une carte mentale remplie de projets à venir ! Certains concernent la langue française ou d’autres langues, d’autres sont des variantes ou des compléments du livre existant. Il y a aussi des projets d’expositions, de parcours pédagogiques, des posters, des jeux éducatifs. Il y a aussi un projet très singulier concernant le vocabulaire, j’espère qu’il trouvera preneur…
Je ne sais pas si tout cela aboutira, mais je souhaite vivement que Le Français vu du ciel ouvre la voie à une nouvelle manière d’aborder l’enseignement et l’apprentissage du français (et des langues en général).
Sarah Sauquet : Pour finir, que dirais-tu à quelqu’un qui voudrait découvrir la langue française à travers ton livre ?
Marion Charreau : Je lui dirais avant tout qu’il s’agit d’un livre pour se faire plaisir, un compagnon de voyage. Je lui poserais ensuite des questions pour comprendre d’où il/elle part : cerner ses besoins, ses connaissances préalables, ses résistances, ses objectifs et ses motivations. Avec ses réponses, je pourrais lui indiquer comment utiliser mon livre et d’autres ressources adaptées.
Je lui dirais aussi qu’il y a plusieurs façons de lire et d’apprendre avec Le Français vu du ciel. On peut parcourir la langue en feuilletant l’ensemble, on peut se focaliser sur l’histoire et la progression du personnage sans entrer dans le détail, on peut consulter une carte en particulier pour un besoin précis (ex : comment poser des questions ?).
Je l’encouragerais vivement à réaliser « son » français vu du ciel en construisant ses propres cartes dans un grand cahier blanc, sur des thèmes qui l’intéressent, qu’il doit communiquer clairement ou mémoriser pour longtemps. Et je lui confierais ceci : le livre qu’il tient entre ses mains est né parce qu’un jour, me trouvant devant des personnes voulant apprendre le français, j’ai dû faire mes propres cartes pour apprendre à l’enseigner.











 côté. Mais lorsque les parents de Paul décident de divorcer, tout se complique. Chamboulé, le jeune garçon pourra compter sur l’aide et le soutien de ses voisins, qui iront jusqu’à lui organiser une fête ! Une belle histoire de solidarité, d’amitié, d’amour, dans un immeuble de Francfort.
côté. Mais lorsque les parents de Paul décident de divorcer, tout se complique. Chamboulé, le jeune garçon pourra compter sur l’aide et le soutien de ses voisins, qui iront jusqu’à lui organiser une fête ! Une belle histoire de solidarité, d’amitié, d’amour, dans un immeuble de Francfort. Littérature jeunesse oblige, de nombreux auteurs offrent de belles et touchantes histoires sur la solidarité entourant les enfants, lorsque ceux-ci vivent des situations difficiles. C’est le cas de Mei, dans le roman Tu peux pas rester là de Jean-Paul Nozière. La jeune fille vit avec sa mère Hua, dans une petite ville de province. Mais les gendarmes de la ville ont reçu l’ordre d’expulser les « sans-papiers », et la mère et la fille sont dans ce cas… Impossible pour les habitants de ne rien faire, et une chaîne de solidarité va rapidement se monter : amis, directrice de l’école, inconnus… tous se mobilisent. Un roman fort, qui ne peut laisser indifférent.
Littérature jeunesse oblige, de nombreux auteurs offrent de belles et touchantes histoires sur la solidarité entourant les enfants, lorsque ceux-ci vivent des situations difficiles. C’est le cas de Mei, dans le roman Tu peux pas rester là de Jean-Paul Nozière. La jeune fille vit avec sa mère Hua, dans une petite ville de province. Mais les gendarmes de la ville ont reçu l’ordre d’expulser les « sans-papiers », et la mère et la fille sont dans ce cas… Impossible pour les habitants de ne rien faire, et une chaîne de solidarité va rapidement se monter : amis, directrice de l’école, inconnus… tous se mobilisent. Un roman fort, qui ne peut laisser indifférent. de foot de Tanzanie, après un premier match contre l’Allemagne, est invitée à jouer le match retour en Europe. Mais effectuer un tel déplacement n’est pas chose aisée ! Il faudra tout le courage et la conviction des jeunes de l’équipe pour créer un large élan de solidarité et permettre au match de se jouer.
de foot de Tanzanie, après un premier match contre l’Allemagne, est invitée à jouer le match retour en Europe. Mais effectuer un tel déplacement n’est pas chose aisée ! Il faudra tout le courage et la conviction des jeunes de l’équipe pour créer un large élan de solidarité et permettre au match de se jouer. éruption solaire. Et comme si ce n’était pas suffisant, une terrible épidémie décime les survivants. Et on en rajoute une louche : la contamination par le virus rend les malades particulièrement agressifs. Difficile de pouvoir vivre, et même survivre, dans des conditions pareilles. C’est au prix d’une nécessaire entente et solidarité que Julia, Shawn et Mouette vont se battre pour s’en sortir…
éruption solaire. Et comme si ce n’était pas suffisant, une terrible épidémie décime les survivants. Et on en rajoute une louche : la contamination par le virus rend les malades particulièrement agressifs. Difficile de pouvoir vivre, et même survivre, dans des conditions pareilles. C’est au prix d’une nécessaire entente et solidarité que Julia, Shawn et Mouette vont se battre pour s’en sortir…