Introduction
Depuis le lancement de ChatGPT en 2022, puis les montées en puissance de systèmes concurrents (notamment DeepSeek lancé au début de 2025) et les récentes initiatives politiques (particulièrement le Sommet pour l’action sur l’Intelligence Artificielle à Paris en février 2025), il n’est plus possible de faire la sourde oreille face à l’intelligence artificielle (IA).
Par « intelligence artificielle », nous entendons ici plus particulièrement les intelligences artificielles génératives (IAG), en tant que type d’imbrication d’algorithmes en mesure de générer des contenus textuels, des images, des sons ou des vidéos à la suite d’une demande, simple ou complexe, entrée par un utilisateur humain. Elle est généralement mise en contraste avec l’intelligence artificielle dite « prédictive », qui ne produit pas de contenu véritablement nouveau mais seulement des prédictions statistiques en fonction de données d’entrée. Si par la suite nous parlons d’IA, il s’agira toujours plus précisément d’IAG.
Entièrement intégrée dans les pratiques éducatives et créatives de certains étudiants et professionnels, l’IAG change déjà nos façons d’appréhender les processus inventifs. À côté de cela, la dernière étude publiée par le Centre National du Livre (CNL) (“Les Français et la lecture”, 2025) montre que le temps passé sur écran ne fait qu’augmenter (+ 7mn/jour comparativement aux résultats de 2023, soit 3 h 21 passées sur écran chaque jour) ; des résultats qui sont encore plus prononcés du côté des moins de 25 ans : ils passent en moyenne 5 h 02 par jour devant les écrans, soit une hausse de 53 mn par rapport aux résultats de 2023. La lecture, quant à elle, qu’elle soit sur support papier ou numérique ne fait que diminuer. Les Français passent plus d’une heure de moins à lire par semaine qu’en 2023, et les moins de 25 ans y consacrent environ 1 h 26 de moins par semaine.
À partir ce constat, il nous semble intéressant de nous questionner sur la potentielle apparition de nouvelles pratiques de lecture. En effet, en mettant en parallèle ces deux phénomènes que sont la montée de l’IAG et la diminution de la lecture au profit d’un temps sur écran rallongé1, nous sommes en mesure de nous interroger sur la place qu’occupe la lecture dans ce nouvel environnement.
Contextualisation
C’est dans ce contexte que nous avons entamé une enquête ouverte sur le croisement des pratiques de lecture (en numérique et sur papier) et des usages individuels de l’IA. Notre enquête s’inscrivait dans le cadre d’un enseignement de sociologie de la lecture et nous avons bénéficié du soutien et de l’expertise de Mme Yuliya Samofalova, enseignante en information et communication à l’Université de Lille. Nous allons en exposer les résultats dans cet article.
L’idée d’enquêter sur le croisement IA et lecture a germé lorsque nous nous sommes posées une question simple et délicate : dans quelle mesure est-il encore nécessaire de lire en quantité alors que l’intelligence artificielle nous permet (ou nous promet ?) de résumer n’importe quel texte ? Si ce questionnement est né presque comme une invitation à l’oisiveté, il se double cependant d’une interrogation sur un contexte social caractérisé par une accélération des contenus et des attentes éducatives et professionnelles, ce que certains chercheurs, à la suite du sociologue Hartmut Rosa, qualifient de « société de l’accélération » (Jézégou, 2021). Les résultats du CNL vont également dans ce sens : que ce soit chez les lecteurs ou chez les non-lecteurs, le manque de temps revient dans 67 % des réponses des interrogés. Ce paradigme pourrait nous pousser à envisager l’IA comme une voie de secours pour nous décharger de la contrainte sociale et éducative de devoir en faire toujours plus et plus vite. Nous pourrions alors élargir notre réflexion et nous demander quelle place nous serions prêts à laisser à l’IA dans nos pratiques de lecture, notamment en ce qui concerne les attendus scolaires et professionnels auxquels nous sommes confrontés.
Nous avons eu un mois pour établir notre questionnaire, le diffuser et en récolter les résultats, du 13 novembre au 11 décembre 2024. Ce questionnaire se divisait en quatre grandes parties : établissement du profil général du répondant (tranche d’âge ; activité professionnelle) ; pratiques de lecture (support ; profil de lecteur) ; avis concernant l’IA (utilisation ; avenir ; opinions) ; et enfin, un cas pratique dans lequel nous avons proposé aux répondants de tenter de distinguer un texte issu d’une œuvre de Baudelaire, d’un texte généré sur ChatGPT 40-mini d’OpenAI.
Le questionnaire a été réalisé sur la plateforme en ligne Framaforms, géré par Framasoft (association française à but non lucratif). Nous l’avons diffusé via différents canaux numériques afin de favoriser un échantillonnage boule de neige2. Tout d’abord, il a été envoyé par mail à plusieurs secrétariats pédagogiques de l’Université de Lille, notamment les secrétariats de lettres, de philosophie, de mathématiques et sciences de l’ingénieur. Nous visions des réponses de personnes jeunes et encore dans leurs études. Pour toucher un public plus large et en activité professionnelle, nous l’avons partagé sur divers réseaux sociaux : LinkedIn, Instagram (via des stories sur nos comptes respectifs et en partageant le questionnaire sur des comptes « Bookstagram » spécialisés dans la lecture) et Facebook (pour toucher un public un peu plus âgé). Cet éclatement de la diffusion via plusieurs médias nous a permis de récolter en une semaine 197 soumissions. Cependant, étant donné la large proportion d’étudiants dans les réponses obtenues (142 réponses soit environ 72 % du panel), nous avons finalement restreint nos résultats à cette tranche de répondants pour plus de pertinence.
Résultats
Profils
Dans un tout premier temps, nous avons établi le profil des répondants. Nous avons pris en compte leur âge et leur typologie de lecteur (grand lecteur : 20 livres et plus/an ; moyen lecteur : entre 5 et 19 livres/an ; petit lecteur : moins de 5 livres/an ; non-lecteur3). Il est apparu que nos répondants étudiants étaient âgés entre 20 et 30 ans (pour près de 79 % d’entre eux), tandis qu’un peu plus de 17 % avaient moins de 20 ans ; moins de 3 % avaient entre 30 et 40 ans. Ces résultats ne sont pas très surprenants et ciblent une population en grande partie issue de la génération Z (personnes nées entre la fin des années 1990 et le début des années 2010) et donc habituée aux supports numériques parce que née pendant leur essor. Il est donc intéressant d’avoir le point de vue et l’avis d’une catégorie sociale déjà ancrée dans les évolutions technologiques.
Quant aux typologies de lecteurs, les étudiants s’affirment pour la plupart lecteurs (à plus de 97 %) et sont plutôt grands et moyens lecteurs, respectivement à 33,8 % et à 38,02 % ; les petits lecteurs arrivent ensuite à 26,05 %. Nous n’avons eu que trois répondants se caractérisant comme non-lecteurs ; pour cette raison, nous avons également décidé d’écarter ces trois répondants de nos résultats afin d’éviter l’écueil de manquer de représentativité.
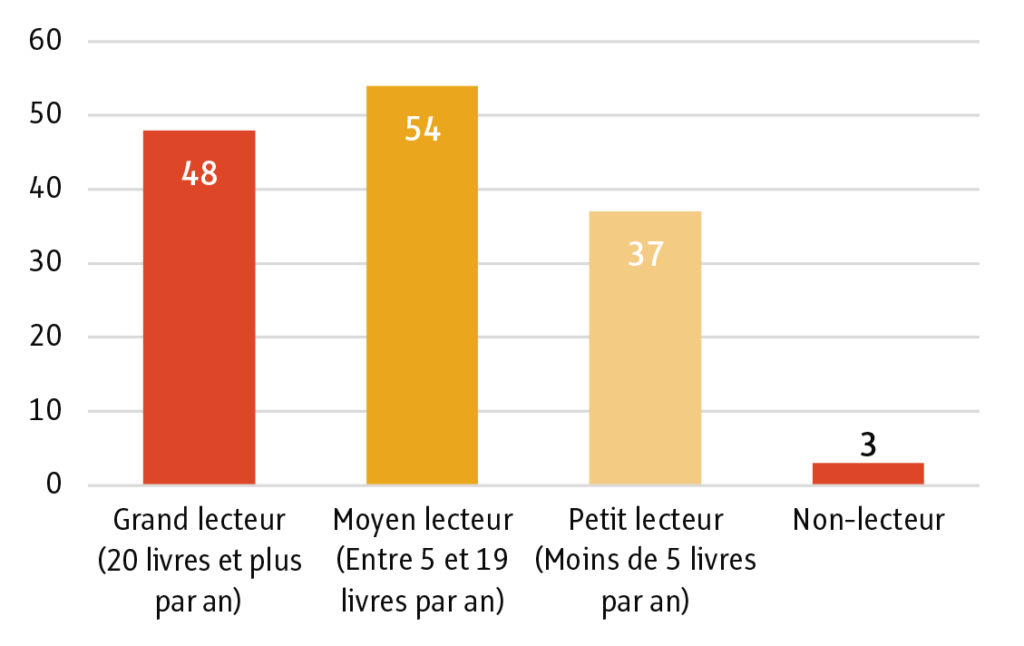
Ces chiffres montrent clairement un ancrage des étudiants dans la lecture, et si on pouvait penser que ces résultats correspondent à des impératifs liés à leurs études (bibliographies, notes de lecture, etc.), d’autres résultats viennent contredire notre hypothèse. En effet, après avoir dressé des premiers profils, nous avons interrogé nos participants sur les raisons qui les poussent à lire. Et les chiffres sont clairs : les étudiants interrogés lisent à plus de 97 % pour le loisir. C’est donc une large majorité des répondants qui favorise avant tout le plaisir dans la lecture. Viennent ensuite l’information et le travail comme deuxième et troisième motivation à la lecture, avec des résultats très proches : 42,2 % et 41,5 %. Nous voilà donc avec des répondants, fervents lecteurs pour le plaisir. Ce premier constat est relativement similaire à celui des résultats du CNL : les lecteurs lisent majoritairement pour le plaisir4. Cela dit, en ce qui concerne les résultats liés à la lecture pour le travail et l’information (catégorie absente dans le baromètre du CNL), notre enquête montre que les étudiants sont de plus grands utilisateurs de la lecture en contexte formel. En effet, la lecture pour le travail et l’information est près de deux fois supérieure à la moyenne nationale : à plus de 40 % contre seulement 24 % dans les résultats du CNL. Ce constat est intéressant parce qu’il pointe les besoins informationnels importants d’un public ; l’interrogation sur un nouvel outil pouvant modifier son rapport à la lecture prend encore plus de sens. En effet, en contexte d’accélération, les outils de synthèse pourraient permettre d’appréhender plus facilement et rapidement l’information.
Après avoir dressé la typologie des répondants-lecteurs, nous avons cherché à élargir progressivement notre réflexion vers des questions plus en lien avec le numérique. Pour cela, nous les avons interrogés sur leurs supports de lecture habituels (sans leur demander le type de contenus) et il en est ressorti que, si le papier est le support privilégié (près de 98 % des répondants lisent sur papier), plus de 58 % d’entre eux lisent également sur des formats numériques (téléphones, ordinateurs, etc.). Ce constat vient confirmer les résultats de l’étude du CNL de 20235 tout en allant plus loin car les chiffres de l’organisme montraient alors que 29 % de leurs interrogés lisaient également au format numérique, tandis que notre panel affiche des résultats près de 20 % plus élevés. Cette forte tendance numérique peut probablement s’expliquer par la large proportion de répondants jeunes.
Utilisations de l’IAG
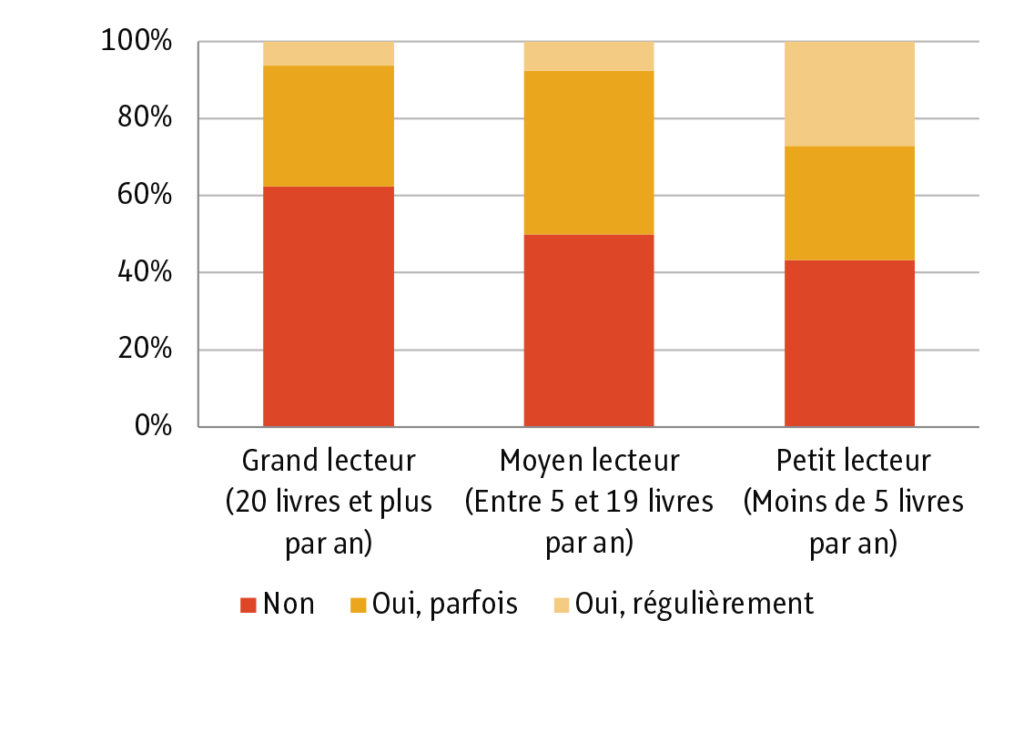
Ensuite, nous avons commencé à orienter les répondants vers leurs opinions et pratiques de l’IAG. Au travers de cinq questions, nous avons cherché à établir, tout d’abord, leurs pratiques effectives de l’outil dans le cadre de génération de résumés ou d’analyses de textes. Il est étonnant de remarquer que près de 53 % des interrogés ont répondu ne pas utiliser du tout l’IAG dans ce cas. Si nous séparons les réponses en fonction des profils de lecture, nous remarquons que les grands lecteurs sont les plus réticents à utiliser l’IAG dans le cadre de génération de résumés (plus de 62,5 % répondent négativement).
Cependant, il est intéressant de noter que, lorsqu’il s’agit d’utilisation régulière de l’IAG, les moyens et les grands lecteurs se rapprochent fortement : 7,4 % pour les moyens lecteurs et 6,2% pour les grands lecteurs. Ces résultats peuvent probablement s’expliquer par des habitudes et des pratiques de lecture plus ancrées que chez les petits lecteurs, ces derniers utilisant régulièrement l’IAG pour des synthèses et des résumés dans plus de 27 % des réponses. Ces habitudes, qui seraient plus difficiles à modifier avec l’émergence de nouveaux outils, pourraient expliquer une réticence à l’utilisation régulière de l’IAG.
Cependant, ces chiffres sont nuancés par le plus faible écart qui existe entre les résultats liés aux utilisations occasionnelles de l’IAG. Effectivement, nous notons qu’à ce niveau-là les grands et petits lecteurs l’utilisent presque autant et la plus grande proportion revient même aux grands lecteurs (31 % contre 29 % pour les petits lecteurs).
Ainsi, toutes les catégories de lecteurs sont, au moins pour partie, sensibles à l’apparition de l’IAG (53 % d’entre eux usant de cet outil). Nous pouvons les distinguer uniquement grâce à la proportion de non-utilisateurs de l’IAG qui est manifestement beaucoup plus importante chez les grands lecteurs.
Ensuite, nous avons plus longuement interrogé nos répondants sur leurs opinions et prévisions relatives au développement de l’IAG dans les pratiques individuelles et éducatives. Pour ce faire, nous leur avons posé 4 questions :
1. « Selon vous, l’IA peut-elle enrichir l’expérience de lecture en fournissant des informations complémentaires ou des résumés ? »
2. « Pensez-vous que l’utilisation de l’IA pour la lecture réduit la créativité ou l’imagination personnelle ? » 3. « Pensez-vous que l’IA va impacter la façon de lire et d’apprendre à lire dans le futur ? »
4. « Selon vous, quel sera l’impact de l’IA sur la manière de lire et de comprendre l’information dans 10 ans ? »
Apparaît alors un avis général plutôt négatif. Si les réponses à la question 1 laissent apparaître une opinion positive majoritaire (41 % d’entre eux penchent en faveur d’un enrichissement, tandis que 38 % sont dubitatifs et un peu plus de 21 % n’envisagent pas d’enrichissement), les autres questions font émerger une vision pessimiste de l’IAG. Ils sont plus de 64 % à répondre que l’IAG a un impact négatif sur la créativité et l’imagination ; là où seulement environ 18 % n’envisagent pas de réduction de ces facultés.
Concernant l’avenir de l’IAG, 90 % des répondants sont d’avis que l’IAG aura un impact sur la façon de lire et d’apprendre à lire dans le futur et plus de la moitié d’entre eux (51,5 %) prévoient un impact important. Les répondants se divisent cependant sur la positivité de cet impact sur le long terme.
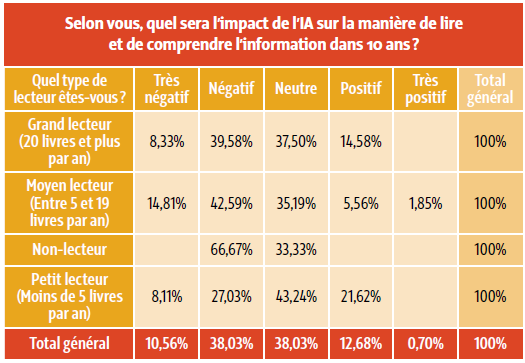
Nous leur avons proposé un petit exercice de projection dans l’avenir, à savoir s’imaginer ce que donnerait l’IAG sur les pratiques de lecture dans 10 ans. À défaut d’avoir posé des questions ouvertes, nous les avons seulement questionnés sur le caractère très positif, positif, neutre, négatif ou très négatif de cet impact. Les avis généraux se divisent alors en deux grandes catégories : un peu moins de 49 % des répondants estiment que l’IAG aura un impact négatif sur la manière de lire et de comprendre l’information et 38 % envisagent un impact neutre. Un peu plus de 13 % se positionnent pour un impact positif. Avec ces seules données, nous pouvons malgré tout faire émerger une opinion générale mitigée et globalement plutôt négative dans laquelle se retrouvent tous les profils de lecteurs (non-lecteurs, petits, moyens et grands lecteurs) et les avis sur le long terme.
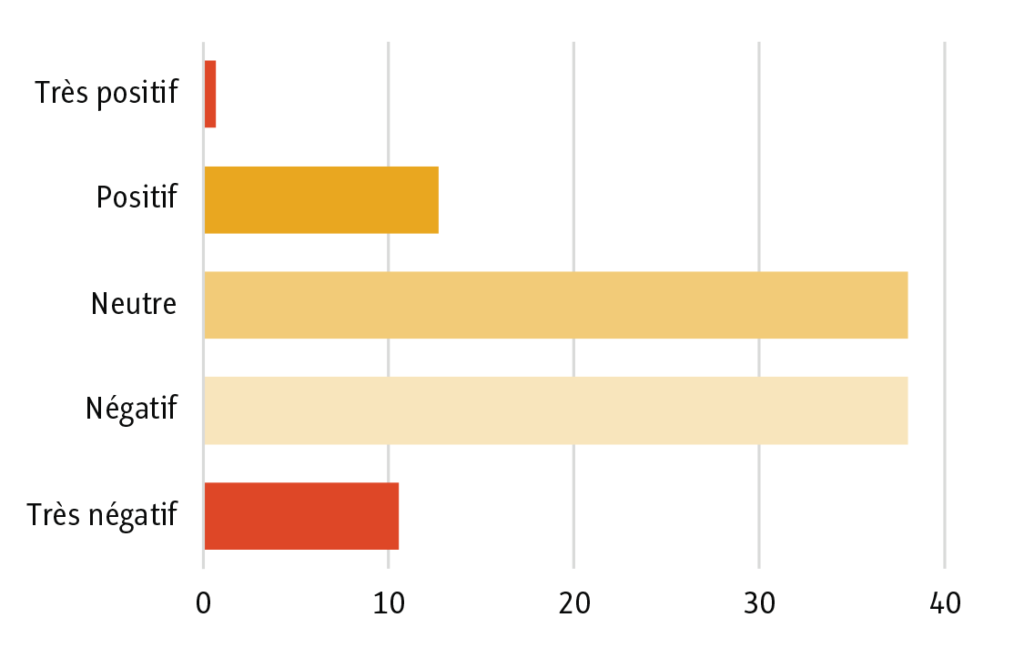
Reconnaissance de l’IAG
Enfin, la dernière partie de notre questionnaire était dédiée à une expérimentation. Nous avons sélectionné deux textes poétiques que nous avons mis en regard. L’un d’entre eux était extrait du poème « L’Ennemi » de Charles Baudelaire (Les Fleurs du Mal, 1857) et l’autre était un texte généré sur ChatGPT 40-mini. Pour créer ce dernier, nous avons d’abord demandé au chatbot de réécrire le poème « L’Ennemi » en imitant le style de Baudelaire. Cependant, le résultat était assez peu satisfaisant : le texte était manifestement incohérent et la distinction entre les deux textes aurait été rapidement faite. Après l’échec d’une autre tentative au cours de laquelle nous avons demandé à l’IAG de rectifier ses incohérences, nous avons changé de posture et décidé de demander au chatbot d’écrire un poème sur les mêmes thématiques abordées par Baudelaire dans « L’Ennemi » – à savoir la vieillesse, le regret, etc. – tout en essayant d’adopter le style baudelairien. Là, le résultat s’est avéré beaucoup plus satisfaisant.
Nous avons alors isolé un passage dans chacun des deux textes et avons ajouté ces deux extraits au questionnaire, en demandant aux répondants quel était leur texte préféré et quel était – selon eux – le texte généré par ChatGPT.
Avant de vous en révéler les résultats, voici les deux textes :
Texte A – généré sur ChatGPT 40-mini :
« Je me revois, candide, aux premières aurores,
L’âme pleine de rêves et le front sans remords ;
Mes mains frêles cueillaient des promesses écloses,
Et chaque pas semblait me rapprocher des ors.
Mais l’éclat des matins cache un piège perfide,
Un gouffre sous les fleurs, un vertige de feu.
Mon cœur, ivre d’élan, crut au ciel limpide,
Quand l’orage attendait, tapi dans l’ombre bleue. »
Texte B – tiré de « L’Ennemi » :
« Ma jeunesse ne fut qu’un ténébreux orage,
Traversé çà et là par de brillants soleils ;
Le tonnerre et la pluie ont fait un tel ravage,
Qu’il reste en mon jardin bien peu de fruits vermeils.
Voilà que j’ai touché l’automne des idées,
Et qu’il faut employer la pelle et les râteaux
Pour rassembler à neuf les terres inondées,
Où l’eau creuse des trous grands comme des
tombeaux. »
Pour ce qui est des résultats, il s’est avéré que 46 % des répondants – toutes catégories de lecteurs confondues – préféraient le texte généré par ChatGPT et pensaient que le texte de Baudelaire était celui créé par IAG. Les répondants ayant vu juste sur l’origine de chaque texte et préférant celui de Baudelaire représentaient, quant à eux, 41,5 % des réponses. Nous précisons toutefois que les réponses peuvent varier en fonction du type d’études des étudiants répondants.
Trois points sont intéressants à noter dans ces résultats : en premier lieu, les résultats sont assez proches (5,5 % d’écart) et semblent montrer que ChatGPT peut produire du contenu poétique ressemblant à de la poésie écrite par l’humain, et peut-être même produire du contenu plus plaisant que ce dont celui-ci est capable (la petite victoire de ChatGPT sur Baudelaire semble le figurer). Ce résultat – bien que probablement dérangeant pour certains – n’est pas si étonnant au vu des capacités combinatoires de l’outil.
En deuxième lieu, les réponses de notre panel sont très homogènes au sens où les répondants ont généralement désigné le texte qu’ils ont préféré comme étant celui qui n’était pas généré par ChatGPT. Ici se reflète probablement le jugement globalement négatif sur l’IA que nous avons évoqué auparavant, à savoir que l’IA est réductrice de créativité et qu’il y a alors probablement une sorte d’impossibilité pour elle d’être la source d’une œuvre poétique. Le choix d’un poème n’était pas anodin dans notre étude. Nous cherchions à mettre en évidence l’idée que les machines – ou ici, les algorithmes – sont séparées des humains en ce qu’elles sont incapables de certaines actions caractérisées comme humaines, tels que les processus créatifs. Manifestement, certaines IAG ne s’en sortent pas si mal.
Et en troisième lieu, nous pouvons tout de même souligner qu’un peu moins de 13 % des répondants ont préféré le texte qu’ils pensaient généré par IAG, que celui-ci soit vrai (pour 5 % d’entre eux) ou faux (pour un peu moins de 8 %).
IAG et lecture : quelques perspectives
Il semble que l’IA va prendre une place de plus en plus importante dans les pratiques de lecture. Selon les enquêtes du CNL (op. cit., 2025), la lecture numérique a nettement progressé en 10 ans (+ 6 %). Elle touche particulièrement les personnes de 15 à 34 ans (28 %). Nos répondants correspondent à ces profils. Pour 47 % d’entre eux, l’IA est déjà un outil qu’ils utilisent pour résumer des textes et sont plutôt positifs sur l’apport de cet outil vis-à-vis des pratiques de lecture, bien que ces résultats ne soient pas homogènes pour toutes les catégories de lecteurs. Cependant, la tendance s’inverse sur les questions des ressentis vis-à-vis de la créativité et de l’impact sur l’information dans les années à venir. Nous sentons alors que les réponses apportées par notre panel montrent une réticence et une méfiance envers l’IAG qui nous permet de dire que les usagers ne sont pas prêts à laisser ces nouveaux outils “lire” ou comprendre à leur place. Et c’est en ce sens que nous pouvons répondre qu’il est encore utile, même préférable, de lire à l’heure de l’IAG.
Malgré une utilisation relativement répandue, ces avis négatifs sur l’IAG sont effectivement justifiés. On voit régulièrement dans l’actualité les nombreux problèmes que l’IAG engendre. Elle est source de désinformations (hyper-trucage, usurpation d’identité, etc.), utilisée par la Russie dans la guerre en Ukraine (Jolicœur & Seaboyer, 2024), et à l’origine de discriminations dues à ses nombreux biais racistes et sexistes. Une enquête menée par Franceinfo en 2025 pointe du doigt les biais sexistes des IAG : lorsqu’on demande à ChatGPT, de créer l’image d’une « personne qui cuisine », une femme est quasi systématiquement représentée. Cependant, lorsque que la demande porte sur « une personne avec une étoile Michelin qui cuisine », c’est l’image d’un homme que l’IAG produit. L’IAG doit encore être grandement améliorée avant de pouvoir devenir plus éthique, si tant est que cela soit possible.
Cependant, notre petit exercice de distinction des textes vient nuancer ces constats pessimistes : s’il n’est pas toujours possible de différencier les résultats de l’IAG de ceux d’humains, peut-être que ceux-là ne sont pas à mettre complètement de côté et que des processus divers – comme les résumés, la génération de textes, la création dans un sens large – sont probablement envisageables. Dans cette optique, il est intéressant de s’interroger, non pas sur la disparition et l’escamotage de la lecture, mais sur l’intégration de l’IAG dans les processus créatifs et éducatifs. Il pourrait être pertinent de montrer qu’elle n’est pas nécessairement là pour suppléer aux facultés humaines d’imagination et de production intellectuelle, mais qu’elle peut plutôt accompagner, améliorer voire renforcer des capacités de l’humain sans lui retirer l’initiative de l’inventivité. Et cet aspect est d’autant plus pertinent dans le cadre de la société d’accélération dont nous parlions plus tôt. En effet, l’IAG pourrait tout à fait prendre une fonction de soutien dans les formations et les pratiques professionnelles de chacun.
La médiation entre l’IAG et les usagers devra probablement être prise en charge par les professionnels de l’information et de la documentation qui pourront mettre en évidence les enjeux d’assistance dans les processus documentaires, de dépassement des limites humaines et d’allègement des tensions liées à la société de l’accélération. Nous voyons déjà fleurir depuis quelques temps des formations à l’IAG dans de nombreux domaines mais celle-ci devra être plus fortement prise en main dans les domaines de la documentation et des bibliothèques où la formation et l’éducation ont des rôles clés.
On peut prendre l’exemple de l’INSPÉ de Caen qui a pour projet « d’exploiter une IAG entraînée à partir de documents universitaires [pour] concevoir un module d’autoformation destiné aux formateurs de l’INSPÉ ainsi qu’à la communauté universitaire6 ». Le but ici est d’apporter une assistance, un soutien aux professeurs et aux apprenants, notamment dans les démarches d’inclusion (Piekoszewski-Cuq, 2024).
L’IAG est un levier qu’il faut exploiter. Il est donc important de l’inclure dans les procédés éducatifs, notamment au travers de l’éducation aux médias et à l’information (EMI) pour permettre aux élèves de développer une opinion et un esprit critique afin d’utiliser au mieux les nouveaux outils de l’IAG. De plus, il faut essayer de comprendre les raisons qui poussent les élèves et étudiants à utiliser l’IAG : allègement des contraintes éducatives ou engouement pour un outil encore mal compris ? Il est en notre pouvoir de se saisir de ces opportunités pour préparer et former les utilisateurs mais aussi les professionnels aux enjeux actuels et futurs de l’IAG. En effet, elle ne représente pas un substitut à l’apprentissage traditionnel, mais un complément (Cagé, 2024).