
« Gouvernementalité algorithmique »
La question de l’algorithme revient, in fine, à des questions relatives à la prise de décision et donc à la gouvernance. Rouvroy & Bern (2013, p. 165) évoquent même le concept de « gouvernementalité algorithmique » en tant que « nouveau régime de vérité numérique [qui] s’incarne dans une multitude de nouveaux systèmes automatiques de modélisation du “social”, à la fois à distance et en temps réel, accentuant la contextualisation et la personnalisation automatique des interactions sécuritaires, sanitaires, administratives, commerciales ». Ainsi, dans les cas cités précédemment, de plus en plus, la décision est prise directement par un algorithme. Nous retrouvons alors une partie de la pensée cybernétique (Delpech, 1972), dont l’étymologie même vient de Kybernete qui signifie « gouverner » en grec, et dans une perspective du passage de la réglementation à la régulation (Supiot, 2005). Ce changement conduit à favoriser le maintien à l’équilibre d’un système (avec une action interne) plutôt qu’une intervention externe sur le système. Si cette approche semble plus rapide et performante (comme l’illustrent les smart contracts sur Ethereum3), elle peut favoriser l’autorégulation en phase avec le capitalisme de plateforme où la donnée est considérée comme le « pétrole » du xxie (avec tous les problèmes associés évoqués par O’neil (2018)).
Il nous semble alors fondamental de questionner la dimension éthique des algorithmes, notre contribution à ce numéro de la revue InterCDI se propose d’apporter quelques éléments théoriques et de réflexion sur la manière dont les professeurs documentalistes peuvent intégrer ce questionnement autour des algorithmes, de l’éthique des algorithmes aux pratiques scolaires et contribuer à la culture informationnelle et numérique de leurs élèves. Il nous semble envisageable d’inscrire ce travail dans le cadre du programme de sciences numériques et technologie de seconde et le programme de numérique et sciences informatiques de la première et terminale.
Éthique et loyauté des algorithmes
Cette question de gouvernance et de prise de décision nous conduit à évoquer la dimension éthique des algorithmes. En effet, ceux-ci doivent prendre des décisions qui affecteront leurs utilisateurs. Comme le rappelle Jean-Gabriel Ganascia, l’éthique vient de « ήθος en grec qui signifie mœurs, coutumes, habitudes » (Ganascia, 2021). D’après lui, l’éthique associée au numérique, et in extenso aux algorithmes, est liée pour partie à la rationalité et à la volonté. Le problème éthique se situe alors sur les interactions êtres humains-machines. En effet, Ganascia note que les interactions humain-machine « doivent aider les humains à soumettre les machines à leurs désirs en évitant qu’elles ne les piègent, voire que certains les utilisent pour les piéger » (ibid.). Face à cela, plusieurs risques liés à l’interaction humain-machine se dessinent :
– Pratiques trompeuses (ex. : spam et autres arnaques en ligne) ;
– Réponse qui modifie le comportement de l’humain (ex. : tentative de manipulation des comportements/opinions d’internautes comme dans le cas du scandale Cambridge Analytica) ;
– Transmission de données personnelles à des tiers (ex. : transmission de données médicales de Doctolib vers des tiers en Allemagne) ;
– Cyber-harcèlement (ex. : diffamation, diffusion d’informations personnelles4).
Comment rester libres et responsables de nos actes ? Les acteurs du numérique gagnent en pouvoir et peuvent prendre des décisions importantes. Ainsi, Facebook ou Twitter se sont arrogés le droit de censurer des contenus qui enfreindraient leurs conditions générales d’utilisation et cela automatiquement, sans aucun autre pouvoir juridique que leurs actionnaires.
Cadrer la question éthique par rapport aux algorithmes, et plus largement au numérique, est aussi complexe du fait de « l’impossibilité à anticiper toutes les applications que l’on peut faire d’une technologie et à décider a priori de ce qui est problématique » (Ganascia, 2021).
Avec ces questionnements éthiques, nous pouvons faire le lien avec les trois lois générales de la robotique formulées en 1942 par Isaac Asimov (auteur notamment d’ouvrages de science-fiction) :
« 1. loi numéro 1 : un robot ne peut porter atteinte à un être humain ni, restant passif, permettre qu’un être humain soit exposé au danger ;
2. loi numéro 2 : un robot doit obéir aux ordres que lui donne un être humain, sauf si de tels ordres entrent en conflit avec la première loi ;
3. loi numéro 3 : un robot doit protéger son existence tant que cette protection n’entre pas en conflit avec la première ou la deuxième loi »5.
Cette première réponse, issue de la science-fiction, est intéressante, mais n’est pas encore implémentable en tant que telle dans les dispositifs informatiques et ne répond pas au problème éthique évoqué. De plus, elle ne tient pas compte des spécificités de notre époque, en particulier le poids des GAFAM et de l’utilisation des données à caractère personnel (Zuboff, 2020) qui est faite. Ainsi se pose la question de la loyauté, en particulier de la loyauté des plateformes. L’Association Francophone des Utilisateurs de Logiciels Libres (AFUL) définit comme loyaux les services qui permettent :
« – à leurs utilisateurs de disposer, dans un format ouvert, de l’intégralité de leurs données ainsi que des données et informations liées nécessaires pour l’exploitation de ces données par un autre fournisseur de service en ligne ;
– à leurs utilisateurs de disposer sous licence libre de tous les logiciels nécessaires pour mettre en œuvre le service en ligne afin de pouvoir bénéficier du même service sur une infrastructure autonome ou exploitée par une tierce partie ;
– à un concurrent potentiel de proposer un service comparable, excluant tout verrouillage juridique empêchant la possibilité d’offrir le même service ;
– un usage du service par tous, partout, et sans discrimination aucune vis-à-vis d’un groupe ou d’une personne ;
– à leurs utilisateurs la garantie du secret absolu et la protection de leurs données, y compris sous forme anonymisée. La fourniture à un tiers de données relatives à l’usage du service ne peut se faire sans un accord préalable explicite de l’utilisateur, au cas par cas. »
Actuellement, en France, la loi pour une République Numérique impose principalement une obligation renforcée d’information à l’égard du consommateur6, une mesure qui semble dérisoire eu égard aux enjeux et aux pratiques des acteurs en présence. Pourtant s’assurer de la loyauté des plateformes et autres algorithmes revient à s’inscrire dans une démarche éthique en interdisant le détournement de certaines données à caractère personnel pour des usages commerciaux ou publicitaires.
Sensibiliser sur la question de l’éthique des algorithmes
Avec la mise en place du cadre institutionnel Digital Competence Framework for citizens (DigComp), transposé en France dans le cadre de Pix (cf. numéro InterCDI 291), intégrer la question des algorithmes, et plus particulièrement de l’éthique des algorithmes, nous semble essentiel pour contribuer à la culture numérique et informationnelle des élèves. En effet, l’algorithme est le soubassement des outils du numérique ; expliciter les enjeux et le fonctionnement des algorithmes (comme ceux à l’œuvre dans la mise en place de bulle de filtres7 pour les cours d’éducation aux médias et à l’information) est alors concomitant avec les objectifs affichés.
Si les élèves utilisent au quotidien de nombreux algorithmes, ils sont peu à se rendre compte de leurs influences sur leurs comportements. Comment favoriser leur prise de conscience ?
Des initiatives intéressantes se développent pour illustrer concrètement les comportements des algorithmes. Ainsi, Rodrigo Ochigame (du Massachusetts Institute of Technology) et Katherine Ye (Carnegie Mellon University) dans leur projet Search Atlas (Ochigame & Ye, 2021) souhaitent contribuer à la « visualisation des résultats de recherche divergents à travers les frontières géopolitiques ». L’outil n’est pour l’instant pas accessible au grand public, toutefois un accès est possible en formulant une demande auprès de l’équipe de recherche.
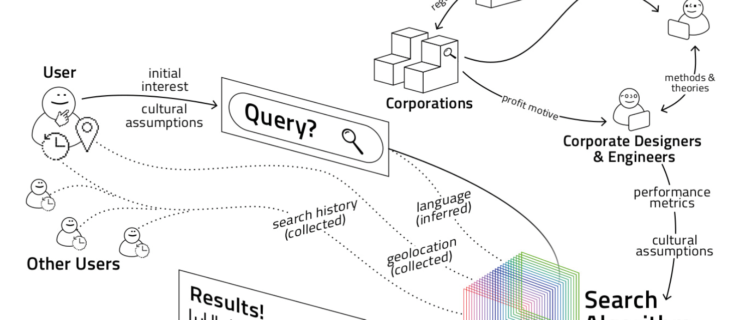
La figure 1 illustre l’interface de l’outil développé par Ochigame et Ye. Dans cet exemple, le concept recherché — god (« dieu » en anglais) — est en haut à gauche. Il est traduit automatiquement en japonais et en arabe pour permettre d’afficher des résultats dans d’autres langues et contextes culturels qu’anglo-saxon.
Trois colonnes présentent les résultats. Dans le premier cas, les résultats de la recherche sur le concept « dieu » en japonais renvoient vers l’acceptation shinto8 du terme. Au contraire, dans les résultats en arabe, « dieu » renvoie vers Allah et l’Islam. Enfin, dans les résultats anglo-saxons, c’est le christianisme qui ressort dans les résultats des moteurs de recherche. Cet outil contribue à matérialiser les biais présents dans l’algorithme de Google.

En effet, la même requête sur Google renvoie donc des résultats contextualisés en fonction de l’utilisateur, de sa langue, et dans son environnement culturel comme les auteurs le soulignent avec la figure 2.
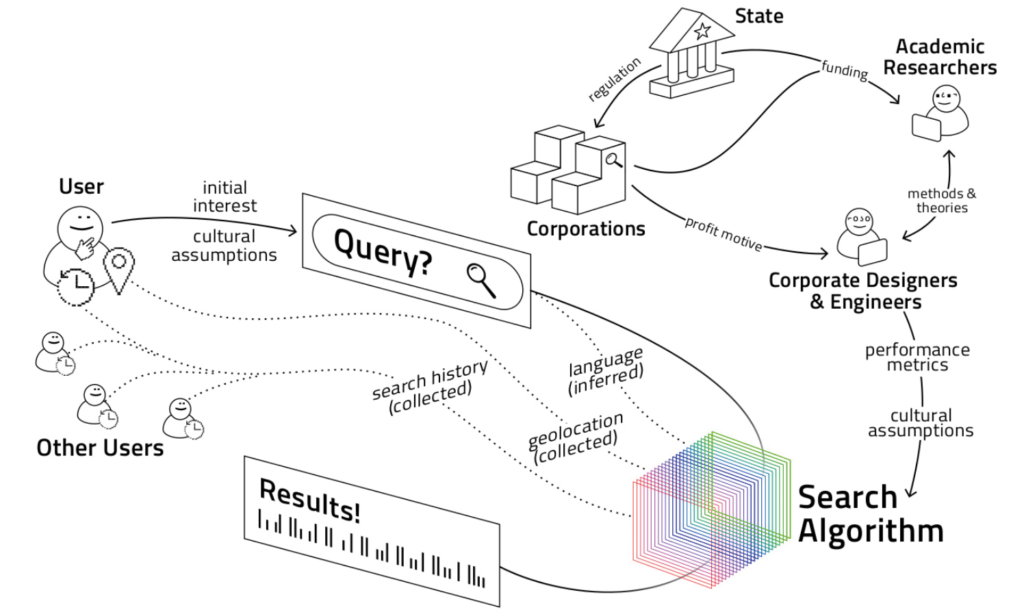
Les résultats d’une même recherche sont alors loin d’être objectifs. En effet, comme le souligne Schmitt (2016) « un algorithme est le résultat de la formalisation d’une procédure qui, une fois implémentée dans un programme informatique, peut alors être rejouée indéfiniment sans intervention (Sandvig, Hamilton, Karahalios et Lanfbort, 2015). Cette reproductibilité laisse à penser qu’un algorithme est un processus mécanique, nécessaire ou autonome qui ne laisserait aucune place à un certain degré de contingence et de jugement individuel ». Contrairement aux prétentions de certains de leurs thuriféraires, un algorithme et son résultat sont fortement influencés par ses concepteurs.
Un travail réflexif peut être mené avec les élèves pour les guider dans la compréhension et l’analyse du fonctionnement des dits algorithmes et des résultats. Complémentaire à cet exemple qui illustre les différentes réponses en fonction de l’environnement culturel ou de la langue, un autre travail peut être réalisé avec les élèves dans le cadre de l’EMI pour qu’ils comprennent les mécanismes mis en place par des acteurs comme YouTube ou TikTok dans le cas des recommandations de vidéos ou plus généralement sur des recommandations de contenus.
En effet, le cas de YouTube est symptomatique. De plus en plus utilisé pour s’informer, le site diffuse de nombreux documentaires et reportages9 qui demandent aux internautes de savoir analyser l’information et prendre un recul critique dessus. Concernant spécifiquement YouTube, en avril 2019, le média Bloomberg10 publie une enquête sur la politique de filtrage du site où l’auteur souligne les choix faits pour favoriser l’engagement sur le site. Se pose alors la problématique éthique liée aux recommandations qui sont faites sur la plateforme, alors même qu’il est fortement utilisé par de nombreux jeunes utilisateurs. Deux exercices complémentaires sont alors envisageables pour sensibiliser les élèves à ces questions.
– Dans un premier temps, mettre en place un carnet de bord des vidéos visionnées (y compris les éléments auxquels nous avons accès comme le nom de la vidéo, l’auteur, sa date de publication, sa durée, le nombre de commentaires, le nombre de vues et de « j’aime » ainsi que sa description) et les suggestions associées à chaque vidéo. Les élèves pourraient ainsi observer sur une période déterminée l’évolution des recommandations sur YouTube11. Ce travail d’observation pourrait être renforcé aussi par la comparaison des suggestions sur YouTube lorsque l’élève est connecté à son compte Gmail et lorsqu’il n’est pas connecté. Nous retrouverons ainsi quelques facteurs sur lesquels s’appuient YouTube aujourd’hui pour recommander des vidéos : contenus que les internautes consultent (vs ceux sur lesquels ils ne cliquent pas), le temps des vidéos visionnées, la popularité (notamment la hausse rapide du nombre de vues), le degré de fraicheur de la vidéo, l’engagement des internautes. Ils pourront alors prendre conscience de la manière dont le site les oriente afin qu’ils restent captifs. C’est aussi une manière d’illustrer concrètement cette économie de l’attention (Citton, 2014).
– Dans un deuxième temps, pour compléter la compréhension du fonctionnement des algorithmes, en particulier ceux utilisés par les GAFAM, il peut être intéressant d’explorer le fonctionnement des réseaux de graphes et de la théorie associée : la théorie des graphes12. En effet, de nombreux sites s’appuient sur des bases de données dites « base de données graphe » pour développer leurs algorithmes et proposer des résultats plus « pertinents » pour l’utilisateur. Il est possible de tester, directement et sans connaissance technique, la base Neo4j depuis un navigateur web depuis : https://sandbox.neo4j.com/. En expérimentant avec Neo4j, nous pouvons matérialiser l’application de la théorie des graphes aux espaces en ligne afin de mieux comprendre de quelle manière les acteurs du numérique structurent la donnée et utilisent ces données structurées pour optimiser les suggestions. Pour travailler spécifiquement sur les suggestions, Neo4j propose directement un jeu de données dédié à la recommandation de films. Voici un exemple de la visualisation qui est offerte par la base de données :
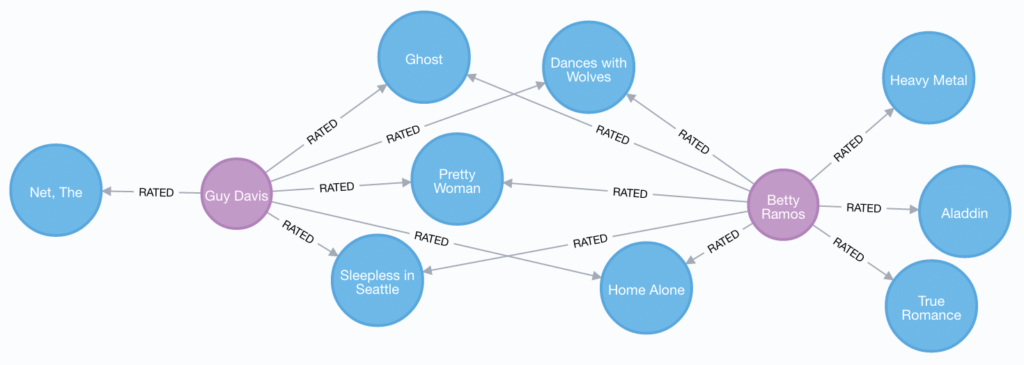
Sur ce cas sont présentes les évaluations de deux internautes. En fonction des votes de Guy ou de Betty (représentés par les points violets), des recommandations de films (points bleus) pourront être faites pour mettre en avant de nouveaux films à visionner lors d’une prochaine connexion. Ainsi, si Betty et Guy regardent les mêmes films (Dances with Wolves, Pretty Woman, etc.) et mettent des évaluations similaires, il est probable qu’un film apprécié par Betty, comme True Romance, pourrait plaire à Guy (et réciproquement). Le système de recommandation automatique devrait alors suggérer à Guy de regarder le film True Romance lors d’une prochaine connexion. Ce système a pour vocation de maintenir captifs au maximum les internautes, car comme l’indiquait Reed Hastings, PDG de la société Netflix, leur seul réel concurrent est le sommeil.
Conclusion
Dans un monde de plus en plus binaire, qui laisse aussi place à moins de nuances, la question de l’éthique des algorithmes renvoie aussi à la question de la formation de citoyens éclairés qui sont à même de comprendre les décisions prises par des algorithmes afin de mettre en place une action corrective si besoin est (i.e. : privilégier des services loyaux et/ou le logiciel libre, autoriser/refuser l’accès à ses données sur des réseaux sociaux numériques comme Facebook pour réguler l’utilisation de ses données à caractère personnel par des tiers, etc.). En effet, l’effectivité du droit à l’opposabilité13 doit permettre à la fois au citoyen de disposer de voies de recours pour obtenir la mise en œuvre effective de son droit et contraindre la puissance publique à une obligation de résultat. Toutefois, comprendre le fonctionnement d’un algorithme demande une littéracie certaine (ex. : capacité à lire du code et à comprendre ce qu’un algorithme fait) qui doit nécessairement compléter les appels à la transparence des algorithmes. Celle-ci est remise en cause par la généralisation d’algorithmes qualifiés de « boîtes noires », en lien avec la mise en place d’algorithmes d’apprentissage profond (comme les réseaux de neurones). Ces algorithmes perdent en intelligibilité pour l’être humain et complexifient particulièrement le travail de rétro-ingénierie pour comprendre le fonctionnement des algorithmes ou pour auditer les comportements des acteurs du numérique.